Perl の勉強がてら Plagger のソースを読んでみた。
ソース張っつけてごちゃごちゃ書くのもあれなので、大体の流れを絵にしてみた。
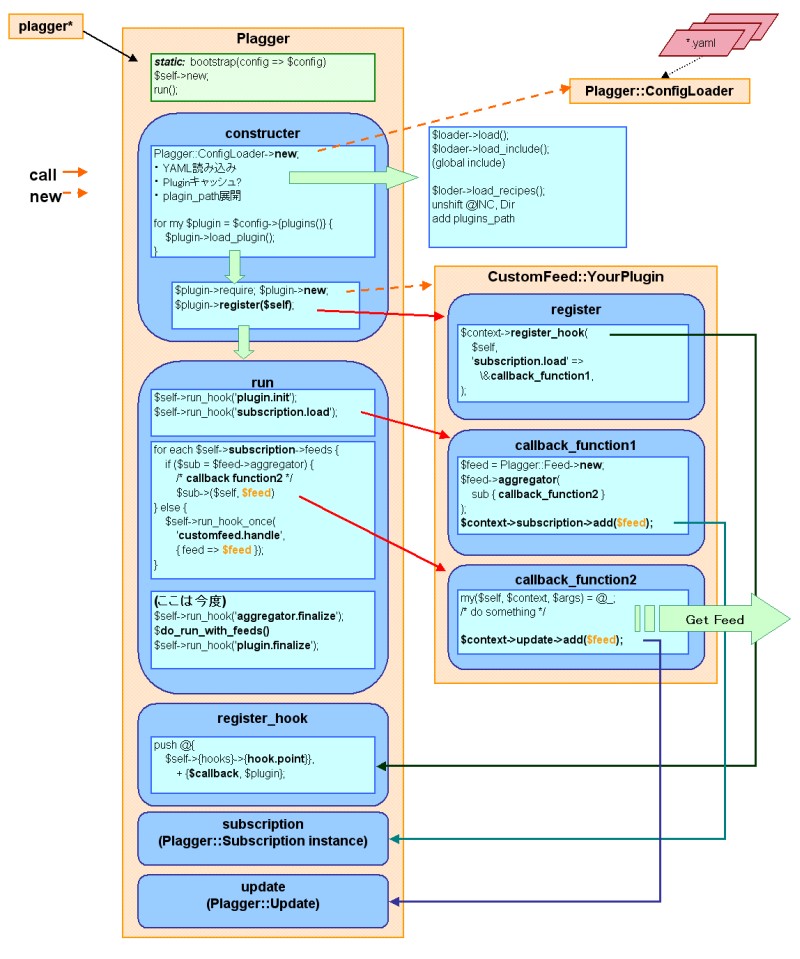
昨日、Plagger について何となく説明してみたけど、Pluginといっても大まかに分類がある。
簡単に言うと入力系、加工系、フィルタ系、出力系(通知系)があり、この図は主に入力系の話。
Plugin の作り方は、自分の register ってメソッドで、$context(plaggerのインスタンス) の
register_hook に対して、エントリーポイントとコールバックをフックする。
入力系の簡単な流れは、subscription.load で、基礎となるデータを持ってきて、customfeed.handle でリンクされる詳細データを加工したりする。
図の例では、subscription.load にフックしているけれども、簡単なデータの取得ならば、customfeed.handle にフックして、基礎データは Subscription::Config て既存のプラグインに持ってきてもらうのが楽チン。(coolbackfunc2のところを実装)
ソース読むまでは plugin 同士のデータのインターフェースはどうやって実装しているのか気になっていたんだけど、Plagger::Feed ってのがその役割を果たしているようだ。
フィルタリング、キャッシング、アウトプット系はまだ目を通してないのでよくわかんないので、また今度。
* 関連記事
suVeneのあれ: Plaggerとは何ぞや

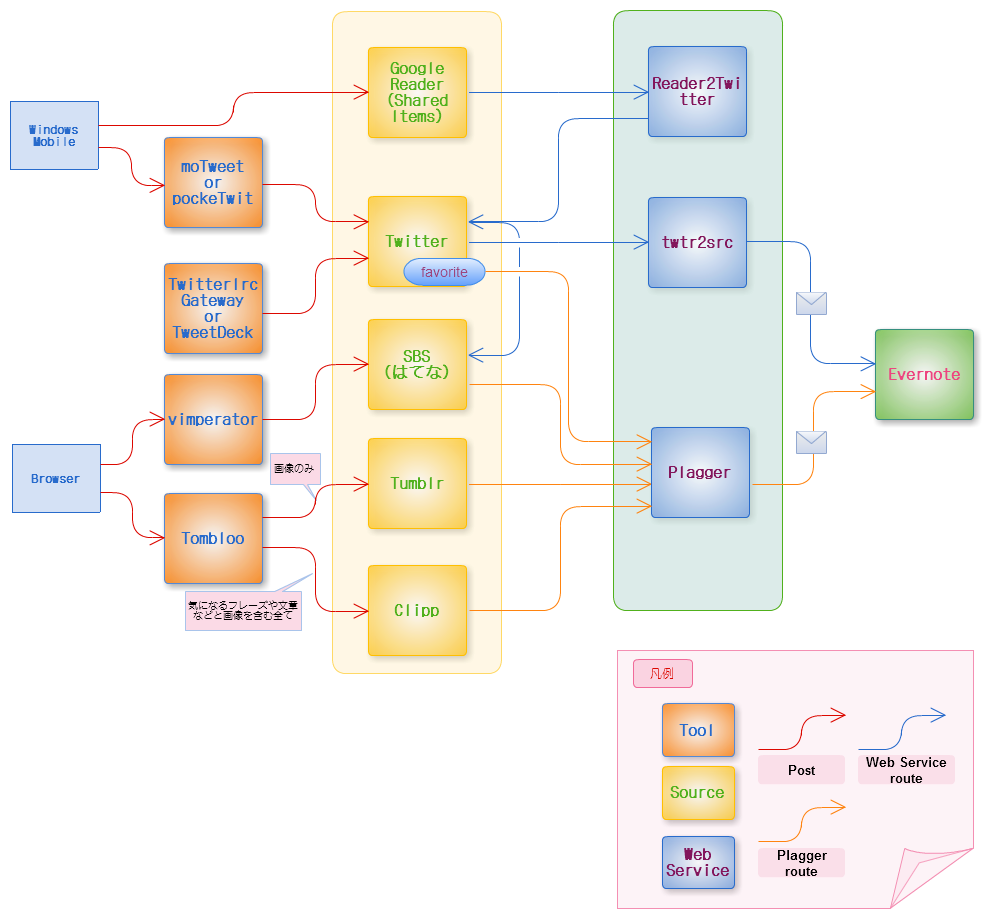

コメント
registor
誰だかわからんがありがとうw 間違えてた!